Esaminiamo ora brevemente alcune caratteristiche del sistema operativo installato sui PC del laboratorio, e che plausibilmente servirà per svolgere le future attività di tesi e di ricerca.
UNIX è un sistema operativo multiprocesso, multiutente, stratificato, a memoria virtuale e con supporto nativo di rete. Non ci interessa approfondire il significato di queste caratteristiche, che sono spiegate un po' meglio in questa nota. Per il momento ci interessa solo sapere che questa lunga espressione afferma in pratica che UNIX è un sistema operativo di uso generale adatto per molteplici applicazioni nella ricerca (dall'acquisizione di dati on-line alla loro analisi off-line, alla pura computazione). Il sistema garantisce inoltre una robusta protezione contro i misfatti degli utenti, dimostrandosi così un ottimo terreno di apprendimento.
Abbiamo già brevemente accennato al fatto che UNIX può contare su un'ulteriore importante caratteristica progettuale: la possibilità di gestire tutte le operazioni di accesso al sistema attraverso il filesystem. Dallo studio del Fortran abbiamo già appreso il comportamento dei file "normali" (sequenze di byte rese permanenti perché scritte su qualche sistema di memoria di massa). Vediamo ora qualche esempio significativo di file "anormali".
/dev e /proc
Ecco qualche file interessante che si può trovare
nella directory /dev di un PC con Linux:
brw-rw---- 1 root floppy 2, 0 Apr 26 1999 /dev/fd0 lrwxrwxrwx 1 root root 8 Feb 24 1999 /dev/floppy -> /dev/fd0Questo è il device (a cui si accede attraverso le normali operazioni valide per i file, come
open, seek,
read, write,
ioctl, close) che comunica
direttamente col primo lettore di dischi floppy. Ovviamente
a questo livello non esiste la nozione di filesystem: il dischetto
è visto come una sequenza di blocchi (da qui la b),
ciascuno di 512 byte.
brw-rw---- 1 root disk 3, 0 May 28 1997 /dev/hda brw-rw---- 1 root disk 3, 1 May 28 1997 /dev/hda1 brw-rw---- 1 root disk 3, 2 May 28 1997 /dev/hda2 brw-rw---- 1 root disk 3, 3 May 28 1997 /dev/hda3 (eccetera...)Attraverso questi device si accede invece al primo disco IDE installato sul PC, e rispettivamente alla prima, seconda, terza,... partizione presente sul disco.
crw-rw---- 1 root lp 6, 0 Apr 26 1999 /dev/lp0 crw-rw---- 1 root lp 6, 1 Apr 26 1999 /dev/lp1Questi device permettono la comunicazione con la prima e la seconda porta parallela del PC (alla quale spesso può essere collegata una stampante).
crw-rw---- 1 root dialout 4, 64 Aug 1 23:45 /dev/ttyS0 crw-rw---- 1 root dialout 4, 65 Apr 26 1999 /dev/ttyS1 lrwxrwxrwx 1 root root 5 Dec 3 1997 /dev/mouse -> ttyS0Idem per le porte seriali. Vediamo che, in questo caso, sembra che ci sia un mouse collegato alla prima porta seriale. I mouse PS/2 usano invece
/dev/psaux.
crw-rw-rw- 1 root root 5, 0 Apr 26 1999 /dev/ttyQuesto device invece non c'entra nulla con i precedenti, e dimostra come i device siano una porta di comunicazione diretta col sistema operativo.
/dev/tty è collegato automaticamente al
terminale (tastiera + dispositivo di output) che controlla il
processo corrente. Che cosa provoca il comando
echo "Hello" >/dev/tty ?
cr--r--r-- 1 root sys 1, 8 May 28 1997 /dev/random cr--r--r-- 1 root sys 1, 9 Aug 1 23:45 /dev/urandomQuesti sono altri device interessanti, e forniscono numeri casuali. La sorgente della casualità è una serie di eventi asincroni interni al sistema, che vengono raccolti nel tempo.
/dev/random
fornisce un numero limitato di numeri casuali (basati sul numero limitato
di eventi asincroni disponibili), mentre /dev/urandom fornisce
un numero illimitato di numeri "pseudo"-random, nel senso
che sono costruiti a partire dal seme costituito dal numero limitato
di eventi asincroni disponibili.
crw-rw-rw- 1 root sys 1, 5 May 28 1997 /dev/zeroUn device spesso utile (anche se a prima vista non sembrerebbe): fornisce una sequenza infinita di zeri.
crw-rw---- 1 root audio 14, 4 Apr 26 1999 /dev/audioPer chi vuole un po' di intrattenimento, questo device riceve dati audio con compressione logaritmica (U-law) e li riproduce sulle periferiche audio del sistema, se presenti.
lrwxrwxrwx 1 root root 13 Dec 3 1997 /dev/fd -> /proc/self/fd lrwxrwxrwx 1 root root 4 Dec 3 1997 /dev/stderr -> fd/2 lrwxrwxrwx 1 root root 4 Dec 3 1997 /dev/stdin -> fd/0 lrwxrwxrwx 1 root root 4 Dec 3 1997 /dev/stdout -> fd/1Sempre più interessante: possiamo qui accedere a standard input, standard output e standard error del processo corrente. Ma che cos'è mai
/proc/self/fd ?
/proc è una directory, presente solo su alcuni sistemi Unix
(fra cui Linux), che permette di accedere attraverso il filesystem
allo spazio di memoria virtuale utilizzato dai processi, ai file che i
processi stessi hanno aperti, ed anche a tante altre informazioni
relative al funzionanento immediato del sistema. Inutile dire che i file
presenti nella directory proc non sono file "normali", ma sono
molto utili. Ad esempio:
> cat /proc/meminfo
total: used: free: shared: buffers: cached:
Mem: 64708608 62943232 1765376 39866368 1323008 14729216
Swap: 267771904 29421568 238350336
MemTotal: 63192 kB
MemFree: 1724 kB
MemShared: 38932 kB
Buffers: 1292 kB
Cached: 14384 kB
SwapTotal: 261496 kB
SwapFree: 232764 kB
oppure:
cat /proc/devices Character devices: 1 mem 2 pty 3 ttyp 4 ttyS 5 cua 7 vcs 10 misc 14 sound 36 netlink Block devices: 1 ramdisk 2 fd 3 ide0 8 sd 9 md
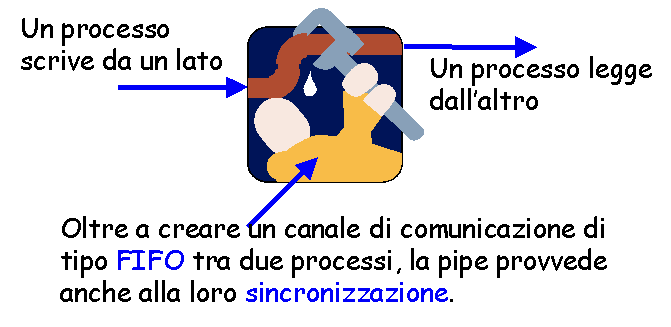
Sappiamo già che ad ogni processo, non appena viene creato, sono collegati almeno tre canali di comunicazione, rappresentati dai file descriptor 0, 1 e 2:
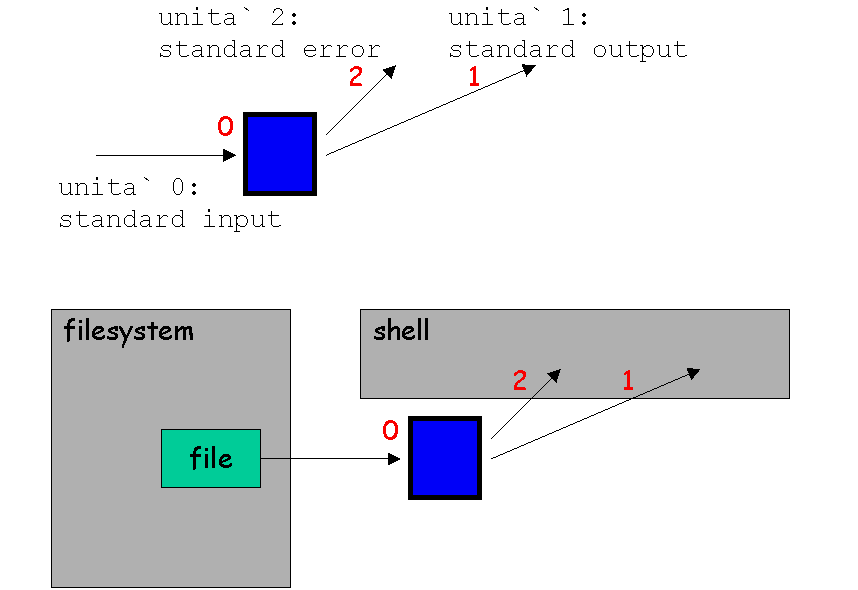
Che succede allora, quando i processi vengono concatenati?
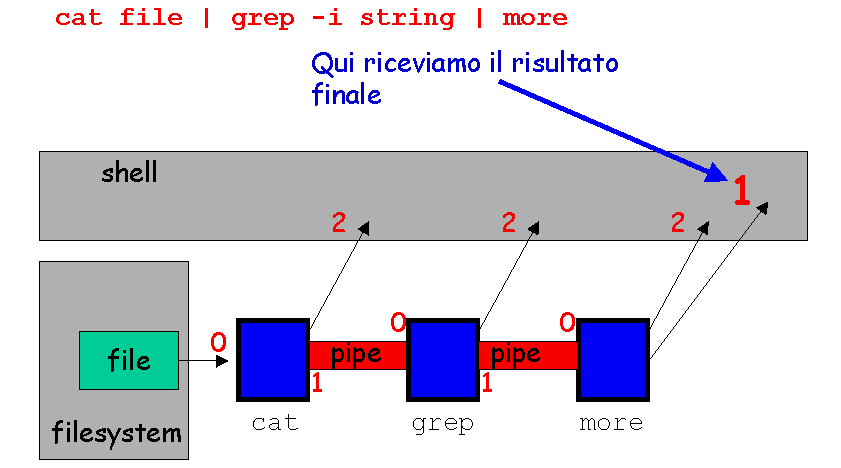
Un altro meccanismo la cui efficienza è stata fra le principali considerazioni
progettali di UNIX è quello della creazione di sottoprocessi. Tutte le
attività che avvengono nel sistema al di fuori del kernel sono
infatti inserite in una gerarchia di processi, tutti generati all'origine
da un unico processo "padre", init, contrassegnato dal numero 1.
Quando su utilizza il sistema attraverso la shell, vengono
normalmente creati uno o più sottoprocessi per ogni comando che viene
eseguito.
La creazione di un sottoprocesso è regolata da due chiamate di sistema, ovviamente accessibili dalla libreria C:
pid_t fork(void);
fork è zero, mentre per il processo
"padre" è il numero identificativo (PID) del "figlio" creato.
int execlp( const char *file, const char *arg, ...);
file ed eventualmente
reperibile nel PATH corrente. arg è il primo
di una lista di argomenti che
possono essere inviati all'eseguibile. La lista deve essere terminata da
un NULL.
In questo  viene dettagliato il meccanismo utilizzato ad esempio dalla shell per eseguire
il comando
viene dettagliato il meccanismo utilizzato ad esempio dalla shell per eseguire
il comando cat /proc/meminfo.
argc, argv[]
Finalmente siamo in grado di capire cosa sono argc e
argv[], che abbiamo sempre incluso nella definizione delle
nostre funzioni main. Ogniqualvolta il sistema esegue un
exec, trasferisce all'eseguibile che viene chiamato una serie
di argomenti (trasferisce anche una serie di parametri, il cosiddetto
environment, ma questa è un'altra storia...).
Questi parametri sono sempre una serie di stringhe di caratteri, e
possono essere utilizzati all'interno del programma. Proviamo ad esempio
ad utilizzare queste informazioni modificando uno dei nostri ultimi
esempi:
La possibilità di specificare gli argomenti di un programma sulla linea
di comando facilita la composizione di comandi nella shell. I singoli
eseguibili, la cui funzionalità individuale può essere molto semplice
e modulare, vengono collegati da pipe. Nei sistemi UNIX sono già
disponibili molti eseguibili semplici che si prestano a questo gioco di
costruzione (ad esempio grep, sort, more,
sed, eccetera).
Esercizio: Provare a collegare via pipe con utility di sistema qualcuno dei programmi già sviluppati.