Nell'analisi dei tipi di dati aggregati fatta qualche tempo fa abbiamo scoperto i vantaggi di poter allocare dinamicamente, leggere e scrivere intere strutture di dati, ma abbiamo trascurato un'importante possibilità: quella di includere nelle strutture di dati puntatori ad altre strutture, come in questo esempio:
typedef struct measurement_s
{
char observer_name[80];
date_time dt;
double temperature;
double value;
char comments[120];
struct measurement_s *next;
} measurement;
Questa possibilità permette di organizzare collezioni di strutture che, rispetto alle semplici sequenze (array), offrono ulteriori vantaggi utilizzabili in diverse situazioni.
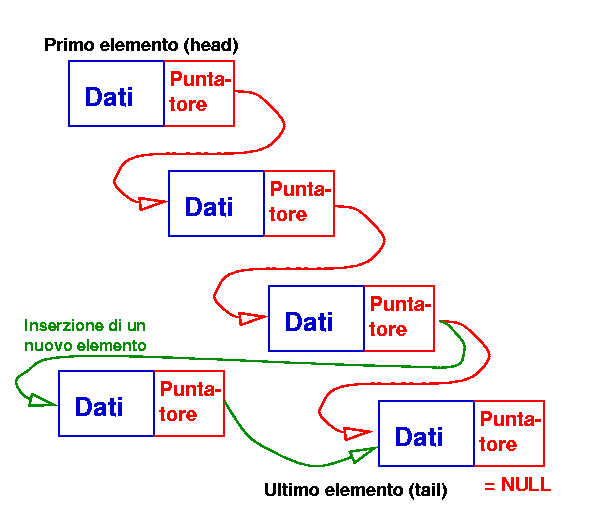
La prima e più semplice possibilità è quella di concatenare gli elementi aggiungendo ad una struttura un puntatore alla struttura successiva. Questo consente di realizzare una lista di elementi o strutture:
Quali sono le differenze rispetto ad un semplice array?
L'inserimento di un nuovo elemento in mezzo alla lista, non richiede
di ricavare uno spazio per il nuovo elemento. In altre parole
non richiede di copiare dati da una parte all'altra della memoria,
un'operazione che dipende linearmente dalla quantità di dati da spostare
ed è in generale costosa.
Bisogna però valutare con attenzione le necessità
della struttura di dati da utilizzare. La scelta della migliore struttura
dati è infatti strettamente legata all'uso previsto.
Per esempio, se il numero di accessi diretti (secondo
il numero d'ordine) agli elementi di una collezione di strutture dati
è molto superiore al numero di modifiche (inserzioni e cancellazioni)
necessarie, un array funzionerà meglio di una linked list.
I due tipi di strutture dati servono infatti per scopi differenti. Vediamo ora
un  che mostra l'implementazione più semplice di una linked list.
che mostra l'implementazione più semplice di una linked list.
Una possibile delle varianti include la possibilità di percorrere la lista in tutte e due le direzioni, prevedendo puntatori sia avanti che indietro, e creando così una double linked list:

Possiamo allora rendere leggermente più sofisticato il nostro
approfittando della possibilità di ordinare la lista.
Altre variazioni sul tema sono le multilinked list, che permettono di prevedere vari "percorsi" di ricerca nella collezione di dati, e le liste circolari, nelle quali semplicemente l'elemento finale della lista è collegato all'elemento iniziale.
La mossa successiva (un po' perversa) consiste nel dotare ogni struttura di dati di due o più puntatori "in avanti", creando così una struttura ad albero:

Esiste una vastissima letteratura in Informatica sulle proprietà ed
applicazioni delle strutture ad albero. Uno dei primi problemi,
ad esempio, è stabilire una convenzione per l'attraversamento
completo, per la quale esistono varie possibilità (che possono essere
più o meno adatte all'applicazione che si sta sviluppando).
Notiamo che il sistema più snello per descrivere una procedura di
attraversamento di un albero è quello ricorsivo. Ad esempio
(preorder traversal) :
L'applicazione più potente e diffusa delle strutture ad albero binario è legata alle operazioni di ricerca: una struttura ad albero binario permette infatti di sommare i vantaggi della gestione dinamica delle linked list con la rapidità ed efficienza della ricerca binaria, come vedremo più avanti.
E' interessante spendere qualche parola sull'utilità fondamentale di una buona scelta delle strutture dati, e sulla loro stretta parentela con la natura delle procedure. Questa discussione parte dall'ottima classificazione fatta nel capitolo introduttivo di K. Loudon, Mastering Algorithms with C, O'Reilly.
Quali sono le motivazioni principali che spingono alla buona definizione di una struttura dati?
Già in questa breve descrizione, si nota come la definizione di una
struttura dati porti alla definizione di alcune operazioni standard
per quel tipo di dati (inserzione e rimozione in una lista
o in un albero, attraversamento della lista o dell'albero,
eccetera). Queste operazioni sono talmente connaturate alla struttura dei
dati che risulta opportuno associarle ai dati stessi, e considerarle
una loro specifica "funzionalità". Come vedremo in seguito, questo
concetto viene ripreso ed esteso nei fondamenti della programmazione
orientata agli oggetti.
Ma quali sono le buone ragioni per standardizzare una procedura, in modo che
possa applicarsi a varie circostanze ed al mutare del tipo di dati
considerato?
Ad una procedura che venga ben definita per operare su un problema "standard", con una struttura di dati "standard", in modo ripetibile e riutilizzabile, viene attribuito il nome generico di algoritmo.
I tipi di strutture di dati che abbiamo analizzato (liste e alberi) si prestano a loro volta alla creazione di strutture composte e ibride, che possono trovare varie applicazioni.
Una semplice linked list può essere associata alle operazioni
fondamentali di inserimento e rimozione per funzionare come una coda
(struttura con funzionamento First-In-First-Out - FIFO),
oppure come uno stack (una struttura con funzionamento
Last-In-First-Out - LIFO). Oppure può essere dotata delle
operazioni fondamentali di gestione di un insieme (unione, intersezione,
eccetera...).
Una collezione di liste (o di singoli elementi) dotata di un catalogo di
qualche tipo,
volto a velocizzare la localizzazione di una particolare lista si chiama
hash table, ed ha vastissime applicazioni nelle applicazioni di
database.
Esercizio: Provare ad aggiungere al programma "grafico" la possibilità di organizzare gli oggetti creati in una linked list. Cosa succede quando vogliamo salvare e recuperare la lista su disco?.