Laboratorio di Calcolo 2
proff. A. Andreazza, D. Galli, E. Spoletini, G. Tiana, A. Vairo
Università degli Studi di Milano
Anno Accademico 2004/2005
Lezione 2
Introduzione
Scopo di questa sessione di laboratorio e' di fare pratica con la
definizione
di funzioni e delle tecniche per la misura dell'efficienza di diversi
algoritmi.
Infine verranno dati alcuni suggerimenti su alcuni approcci alla
gestione
di progetti in C, tipici nei sistemi UNIX.
Questa sessione prevede:
- scrittura di un programma per la lettura ed il riordinamento di
un
vettore
- scrittura di una funzione per il riordinamento di un generico
vettore
- valutazione del tempo di calcolo impiegato in funzione della
dimensione
del vettore
- paragone del vostro algoritmo di ricerca con altri algoritmi
- compilazione separata e makefile
L'esercizio
L'esercizio consiste nello scrivere un programma che legge dei numeri
reali
(max 100000), li immagazzina in un vettore, chiama una funzione che
riordina
il vettore ed infine stampa il vettore riordinato. La funzione
dovrà
essere scritta in un file a parte, in modo che si possa facilmente
sostituire
e compilare separatamente.
Poi dovrete sperimentare il programma sui dei file
di diversa dimensione per verificare come il tempo impiegato per il
riordinamento varia con la
dimensione effettiva del vettore e stimare quindi l'ordine di
complessità dell'algoritmo.
Per chi ha tempo si potrà anche confrontare diversi algoritmi.
Infine vedremo come organizzare la compilazione nel caso di progetti
complessi.
main
Per semplicità potremmo scrivere il main in un file ordinamenti.c.
La strutture del main potrebbe essere la seguente:
#include <stdio.h>
int ordina( int , float[] );
int main() {
/* Dichiarazione delle variabili e dimensionamento del vettore di float */
while ( scanf( ... )!=EOF ) {
/* lettura dei dati ed inserimento nel vettore */
}
ordina(...);
/* invocazione della funzione */
/* stampa con printf del vettore dopo l'ordinamento */
return 0; /* Bisogna fornire un valore di ritorno */
}
La seconda riga è una dichiarazione della funzione ordina.
Con essa indichiamo al compilatore che ordina è
una funzione che ha come primo argomento un intero e come secondo
argomento
un vettore di float. Essa resituisce un valore intero. Una
dichiarazione
dice come una funzione appare, non come è fatta.
Il
compilatore ha bisogno solo di questa informazione, per il momento.
Per una dichiarazione sono importanti solo i tipi degli argomenti e
del valore di ritorno. Tuttavia dare un nome agli argomenti può
aiutare l'utente a capire cosa attendersi dalla funzione. Ad esempio la
riga potrebbe essere anche scritta esplicitamente come:
int ordina(int NumeroDiComponenti, float vettore[]);
ed in tal caso si capisce cosa indicano entrambi gli argomenti. Ma
anche
la più semplice:
int ordina(int N, float v[]);
è già abbastanza autoesplicativa.
Una volta scritto il programma principale possiamo provare a
compilarlo.
Non possiamo però fornire un eseguibile, perché ci manca
un'implementazione della funzione ordina (ovvero qualcosa che
dica
al compilatore come tale funzione è fatta). Quindi
possiamo
fermarci allo stadio di semplice compilazione del gcc:
gcc -c ordinamenti.c
che crea un file oggetto, ordinamenti.o.
Una costruzione importante
Nel programma dovrete essere in grado di leggere un numero
indeterminato
di righe dallo standard input o da un file. Per fare questo si
può
usare un ciclo while del tipo:
while ( scanf( /* Eh, no! il formato esatto non ve lo dico! */ )!=EOF ) {
/* codice da ripetere per ogni riga */
}
Analizziamo per un momento questa espressione. In C ogni funzione ha un
suo valore di ritorno (al limite di tipo void). Per scanf
, questo valore di ritorno è il numero di oggetti letti
correttamente,
tranne nel caso in cui venga raggiunta la fine del file. In tal caso,
esso
assume un valore speciale, che indica che non ci sono ulteriori dati da
leggere. Tale valore è indicato da EOF (End Of File).
Cosa
vale EOF è definito nell file header stdio.h
(lo
stesso che contiene le dichiarazione di scanf e printf),
che quindi deve essere inserito con una direttiva #include.
La riga di codice quindi fa due cose:
- per prima cosa chiama scanf per leggere i dati e metterli in
memoria,
- successivamente prende il valore di ritorno di scanf e lo
confronta con EOF:
se i due valori sono uguali significa che la fine del file
è
stata raggiunta ed il ciclo termina.
Per generare un carattere di EOF dal terminale,
bisogna
premere la combinazione di tasti Ctrl-D.
È molto utile avere bene in mente come usare questa costruzione,
dato che risulta utilizzabile nel 90% dei temi d'esame.
La funzione ordina
L'implementazione della funzione ordina può
essere
fatta in un file separato. Supponiamo per semplicità che si
chiami
algoritmo.c. La sua struttura sarà del tipo:
int ordina(int N, float v[]) {
/*
* codice e manipolazione di v
*/
return N; /* dobbiamo fornire un qualche valore di ritorno */
}
A questo punto, all'interno della funzione,N e v
sono oggetti noti, con il loro corretto valore e non c'è bisogno
di inizializzarli né di dichiarli. Gli elementi del vettore v
possono essere indirizzati nel modo usuale: v[0], v[1],
... v[N-1]. Nella vostra
funzione
ci saranno probabilmente dei cicli for per accedere agli elementi di v:
for (i=0; i<N; i++) { ... }
e degli scambi dove opportuno:
temp=v[i]; v[i]=v[j]; v[j]=temp;
Anche questo file, da solo non può dare un eseguibile, quindi
anche in questo caso bisognerà fermare il gcc
dopo
la compilazione:
gcc -c algoritmo.c
che crea un file algoritmo.o.
La costruzione dell'eseguibile
Per costruire l'eseguibile bisogna mettere insieme tutte le parti. Al
gcc
è possibile fornire direttamente dei file oggetto. Il gcc in tal
caso effettua solo lúltimo stadio della compilazione, ovvero
l'invocazione
del linkeri
gcc -o algoritmo ordinamenti.o algoritmo.o
Potremmo anche rifare la compilazione dall'inizio con
gcc -o algoritmo ordinamenti.c algoritmo.c
ma questo è un po' uno spreco.
Test del programma
Una volta riusciti a compilare il programma senza errori, procedete a
verificarne
la funzionalità inserendo manualmente dei valori e
controllando che questi vengano ordinati correttamente.
Quando siete sicuri che il programma funziona potete fargli leggere
dei dati da file potete scaricare file già pronti con 10000,
20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000,
e 100000
valori.
Per far leggere i file al programma, non è
necessario modificarlo, ma
basta ricordarsi l'utilizzo degli operatori di ridirezione >
e <:
- < nomefile, indica alla shell di usare
il file
nomefile come standard input per il comando da eseguire;
- > nomefile, indica alla shell di usare
il file nomefile
come standard output per il comando da eseguire.
Quindi una riga come:
nomeprogramma < nomefileinput > nomefileoutput
leggerà il file nomefileinput
e scriverà
i risultati nel file nomefileoutput.
Tempo di esecuzione
Per prima cosa si può verificare che il programma funzioni
correttamente,
inserendo un piccolo numero di dati a mano. Successivamente si possono
utilizzare i file file#####.dat che trovate nella home
directory. Gli algoritmi di ordinamento di solito hanno un tempo di
esecuzione
che cresce più che linearmente con la quantità di dati.
Anzi,
dato il vostro algoritmo, come vi aspettate che il suo tempo di
esecuzione
cambi con l'aumento dei dati?
time
Il programma time:
time comando
permette di avere un riassunto del tempo utilizzato per eseguire comando,
sia il tempo totale che quello effettivo di CPU (che di solito è
molto minore, perché le due CPU di labmaster stanno servendo
quasi
una trentina di utenti). Siccome comando può contenere
gli
operatori di ridirezione studiati la volta scorsa, potete leggere
l'input
da file e scaricare l'output su un altro file.
Verificate come si comporta il tempo di CPU variando il numero di dati
da 10000 a 40000. Quanto vi aspettereste per 100000 dati? Se vi viene
più
di un minuto di CPU, è meglio che non proviate a verificare,
altrimenti
rischiate di bloccare la macchina per tutti gli altri utenti.
gprof
Il difetto di time è che non permette di vedere
i dettagli delle singole funzioni, ma a noi non interessa il tempo
necessario
per eseguire il nostro programma, ma solo quello richiesto dalla
funzione
ordina (ovvero dal nostro algoritmo di ordinamento).
Per
avere questo livello di dettaglio (profiling) si può
utilizzare
il programma gprof, che però richiede di modificare
l'eseguibile,
ponendo l'opzione -pg ad ogni passo della
compilazione:
gcc -pg -c ordinamenti.c
gcc -pg -c algoritmo.c
gcc -pg -o algoritmo ordinamento.o algoritmo.o
Se adesso il programma algoritmo viene eseguito normalmente con
./algoritmo < inputfile >
outputfile
oltre al normale file di output, viene creato uno speciale file gmon.out
che contiene le informazioni di profiling. Questo file
può
essere interpetato dal comando gprof,
gprof ./algoritmo gmon.out
che crea una serie di tabelle che forniscono per ogni funzione quante
volte è stata chiamata, il tempo impiegato in essa...
Siccome gprof è più accurato di time,
ripetete l'ultimo passo del punto precedente.
Un po' d'ordine: il makefile
Qual è il vantaggio che abbiamo ottenuto nel dividere il
programma
in diversi file? Per prima cosa, se dobbiamo cambiare qualcosa nel
formato
dell'output o nell'algoritmo di ordinamento, ci basta modificare solo
quella
funzione, senza doverci rileggere tutto il programma. In più,
dopo
la modifica, non dobbiamo ricompilare tutto, ma solo il file
modificato.
Infine, se un nostro amico ci chiede di provare la nostra
funzione,
non dobbiamo passargli tutto il programma, ma solo un file.
Questi vantaggi però hanno come prezzo una maggiore
complessità
della procedura di compilazione.
Con due soli file, sia i vantaggi che gli svantaggi sono minimi, ma
non appena si ha a che fare con un progetto che contiene anche solo una
decina di funzioni, entrambi gli aspetti diventano significativi e la
tecnica
per superare parzialmente gli svantaggi della più complessa
procedura
di compilazione è quella di utilizzare un makefile.
Il makefile contiene l'informazione di cosa è
necessario fare per compilare ogni parte del programma,
codificata
in un insieme di regole per creare dei file a partire da altri. Nel
nostro
caso il makefile sarà fatto cosí:
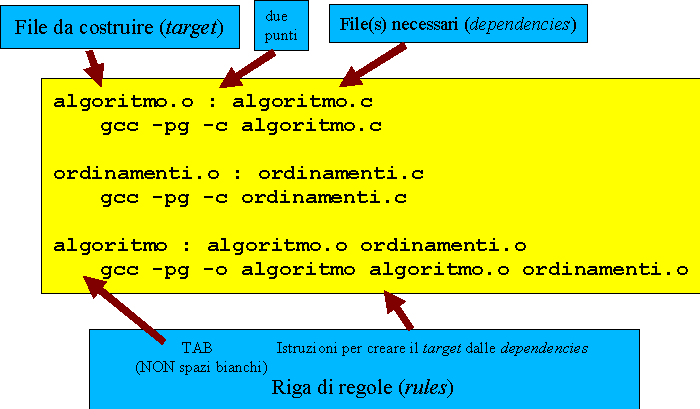
Il comando
make target
cerca nella directory corrente un file chiamato makefile, al
suo interno cerca il target richiesto ed esegue le regole
(possono anche esserci più righe di regole per un target,
ma una sola riga di target:dipendenze) ad esso associate. Il make
controlla anche che i file da cui dipende il target siano
aggiornati
e, se non lo sono, provvede ad invocare le regole che servono a
ricrearli e cosí via.
Nel nostro caso, se dopo aver compilato algoritmo,
modificassimo una riga di ordinamenti.c, allora per
ricreare
la nuova versione di algoritmo, basterà fare:
make algoritmo
ed il make provvederà a ricompilare ordinamenti.o
(ma non algoritmo.o perché non è
necessario)
e poi a creare di nuovo l'eseguibile.
In tal modo una modifica al codice del programma si propaga nel modo
che richiede il minimo sforzo di compilazione.
Provate a costruire il makefile ed a verificare quanto
detto.
Altri algoritmi
La creazione del makefile completa la parte obbligatoria
dell'esercizio.
Chi ha tempo può procedere ad un passo successivo, il confronto
tra diversi algoritmi.
Un primo confronto (fattibile solo con il time)
è
quello di vedere quanto veloce è il vostro algoritmo rispetto al
sort che si poteva usare la volta scorsa.
In più potete scaricare alcuni file contenenti diverse
implementazioni
della funzione ordina:
Modificate il makefile in modo da poter creare degli
eseguibili
con queste funzioni.
Verificate che l'uscita dei diversi programmi sia identica. Per
confrontare
due file, basta dare il comando:
diff file1 file2
se i due file sono identici non c'è nessun output, se
differiscono,
la lista delle differenze viene presentata.
Qual è il programma più efficiente?
Come si compara il vostro algoritmo a bubblesort o a simple?
Osereste provare quicksort su un file di 100000 dati?
Riuscite a capire come funziona quicksort? Purtroppo c'è un
sacco di C che non avete ancora fatto a lezione.
Relazione
Come al solito, prima di lasciare l'aula, siete pregati di riempire un
piccolo formulario
con domande relative allo svolgimento dell'esercizio.