Forse il termine più abusato di questo fine/inizio millennio
è "internet" (entriamo in internet,
andiamo in internet, cercalo in internet...). Una schiacciante maggioranza
di applicazioni di "internet" è codificata in C, e queste applicazioni
rivestono importanza sempre crescente anche in ambiente scientifico
(specialmente per le collaborazioni più grandi ed estese).
Cerchiamo dunque di mettere a fuoco qualche concetto.
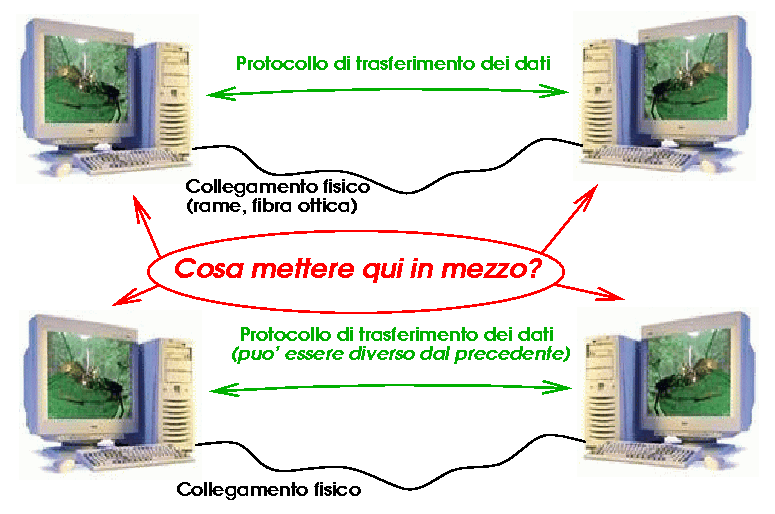
Il concetto di "trasmissione dati" risale almeno al 1875 (codice Baudot), ma per molti anni dopo l'invenzione del transistor (1948), si dovevano risolvere i problemi legati al funzionamento di un computer, prima di poter pensare di collegarne più di uno assieme. Il primo sistema di LAN (Local Area Network) disponibile commercialmente (Datapoint ARC) appare nel 1977. L'idea è ovviamente quella di espandere il canale di comunicazione dati della CPU, attraverso collegamenti a distanza, in modo da poter interagire con il funzionamento di un'altra CPU, mettendo in comune dati e programmi. Il metodo utilizzato per il trasporto fisico dei dati avanza di pari passo con la tecnologia elettronica (e, più recentemente, ottica), e le scelte tecnologiche legate al trasporto fisico dei dati, al protocollo di accesso al trasporto, ed al protocollo di comunicazione prendono rapidamente vie di sviluppo diverse, portando a soluzioni svariate. Non ci occupiamo qui dei problemi della trasmissione dati a questo livello. Questo però era il quadro della situazione nei primi anni '80:
Da sempre interessato ai problemi della logistica, il Department of Defense degli Stati Uniti aveva avviato, già dal 1973, un programma di sviluppo di metodi per la trasmissione dei dati non segreti che potesse sfruttare qualunque mezzo e protocollo di comunicazione disponibile. Come ottenere questo risultato? Implementando un livello di astrazione più alto di quello fisico, legato ad una particolare tecnologia di LAN. Questi alcuni dei problemi da risolvere, al puro livello dell'infrastruttura (senza pensare alle applicazioni):
Il risultato è stata la definizione di un protocollo di trasmissione di "pacchetti" (= "piccole" quantità) di dati, di uso generale, chiamato IP (Internet Protocol):
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ |Version| IHL |Type of Service| Total Length | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Identification |Flags| Fragment Offset | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Time to Live | Protocol | Header Checksum | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source Address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination Address | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Options | Padding | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Example Internet Datagram Header
Nota: Il modello di sviluppo "aperto" di questi standard è in parte responsabile del loro successo. I documenti che definiscono tutti gli standard del protocollo IP e dei protocolli collegati si chiamano RFC (Requests For Comments) e possono essere consultati ad esempio nel sito http://sunsite.cnlab-switch.ch/cgi-bin/search/standard/nph-findstd.
La funzione di IP, dunque, è quella di identificare piccole quantità di dati (vediamo sopra che la lunghezza massima di un pacchetto è di 65536 byte) in modo che possano essere recapitate ad una destinazione anche al di là di parecchie "interfacce" tecniche ed amministrative.
Spesso un'applicazione ha bisogno di identificare meglio un determinato "servizio" sulla macchina di destinazione, oppure di stabilire un "flusso" continuo di dati (il concetto ricorda gli "stream" della libreria standard C). Per questo esistono due principali protocolli che agiscono "al di sopra" del livello di IP.
Il più semplice è UDP (User Datagram Protocol), e semplicemente
permette di identificare un servizio remoto associando
all'indirizzo IP un numero di "porta". UDP garantisce inoltre
anche un controllo
di integrità dei dati, attraverso una semplice checksum (calcolata
ad esempio con qualche strategia di Cyclic Redundancy Check).
Questa la struttura di un header UDP:
0 7 8 15 16 23 24 31 +--------+--------+--------+--------+ | Source | Destination | | Port | Port | +--------+--------+--------+--------+ | | | | Length | Checksum | +--------+--------+--------+--------+ | | data octets ... +---------------- ... User Datagram Header Format
Il protocollo che si occupa di stabilire un "flusso" di pacchetti IP verso
il servizio di destinazione (cioè di stabilire una connessione)
si chiama TCP (Transmission Control Protocol). Ovviamente
la sua struttura è molto più complessa, e non la descriviamo qui
in dettaglio. Vale solo la pena di
sottolineare che, oltre ad identificare i servizi tramite
"porte", TCP assegna "numeri d'ordine" ai pacchetti. La
persistenza della connessione viene verificata controllando che
il servizio remoto risponda con un Acknowledgment Number
corrispondente al numero di sequenza di un pacchetto emesso
"recentemente", entro una certa "finestra" di numeri. Quale sia
il metodo
migliore per regolare l'ampiezza di questa "finestra" è un problema
molto dibattuto, ed in qualche misura ancora aperto. L'unico
concetto semplice ed importante da ricordare a questo proposito è
che le prestazioni (in termini di flusso di dati) di una "connessione" TCP
possono in pratica esibire effetti piuttosto complicati.
Questo anche perché il protocollo ha la possibilità di richiedere la
ritrasmissione dei dati se viene identificato un errore di
trasmissione oppure nell'integrità dei dati.
Ecco la struttura di un header TCP:
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source Port | Destination Port | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Sequence Number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Acknowledgment Number | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Data | |U|A|P|R|S|F| | | Offset| Reserved |R|C|S|S|Y|I| Window | | | |G|K|H|T|N|N| | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Checksum | Urgent Pointer | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Options | Padding | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | data | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ TCP Header Format
Nella pratica la combinazione di TCP ed IP viene utilizzata talmente spesso che il protocollo di trasmissione dati di "internet" viene comunemente identificato come "TCP/IP".
Abbiamo notato come TCP sia in qualche modo un protocollo "costruito" su IP. Questa "gerarchia" di protocolli ha un fondamento concettuale più profondo, sul quale è meglio soffermarsi per un istante.
Come abbiamo visto, l'Internet Protocol può realizzare la sua originale funzione di interconnessione di reti diverse perché introduce un nuovo livello di astrazione. Questo metodo può essere in qualche modo generalizzato ed utilizzato sia come tecnica di programmazione di sistema, che come un criterio guida per la progettazione di interi sistemi informatici.

Il programmatore (utente finale o programmatore di sistema) che si occupa di sviluppare il codice ad un certo "livello" non deve occuparsi dei livelli inferiori, e può considerare che la macchina collegata remotamente in rete risponda solo al livello corrispondente.
La International Standard Organization (ISO) ha definito in modo standard quali sono i livelli di astrazioni applicabili alla interconnessione dei sistemi informativi (OSI, Open System Interconnection). Questo criterio di scansione è spesso utilizzato per semplificare ed organizzare la descrizione degli apparati di rete. Ecco ad esempio come possono venire mappati alcuni protocolli di Internet sulla gerarchia dei livelli ISO/OSI:

L'equivalente del file descriptor, nel caso di una connessione
di rete, si chiama socket. Aprire una connessione richiede
di compiere una serie di operazioni più complesse della semplice
apertura di un file (ottenere l'indirizzo IP del
destinatario a partire dal nome, assicurarsi che il destinatario sia
raggiungibile, eccetera). Inoltre l'implementazione delle socket
nella libreria standard C non è specializzata per un particolare
protocollo di rete (IP), ma è prevista (anche se non molto utilizzata)
anche la possibilità di aggiungere altri meccanismi. Diventano così
abbastanza complesse le operazioni necessarie
per "aprire" una socket in
trasmissione (connect) od in ricezione (listen e
accept).
Per questa ragione, è possibile utilizzare
queste due semplici funzioni per
aprire una socket in trasmissione od in ricezione:
int SHLP_open_and_connect(char *dest_host, unsigned short port);
Cerca di stabilire una connessione TCP diretta all'host dest_host
(identificato per nome o indirizzo IP), alla porta port.
La funzione restituisce l'identificatore della socket
ottenuta, o -1 in caso di errore.
int SHLP_listen_and_connect(unsigned short port, unsigned int timeout, char *caller_id, int caller_id_size); Attende di ricevere una
connessione TCP sulla porta port per timeout
secondi (attende indefinitamente se timeout è zero). Se
caller_id non è NULL, ma punta ad una
stringa pre-allocata di dimensione caller_id_size, nella
stringa viene copiato il nome
o l'indirizzo IP dell'host che ha originato la connessione.
La funzione restituisce l'identificatore della socket
ottenuta, o -1 in caso di errore.
Le chiamate di sistema per inviare o ricevere un messaggio su una socket sulla quale è presente una connessione attiva sono invece:
#include <sys/socket.h>
int send(int s, const void *buf, int len, unsigned int flags);
buf, di lunghezza len byte,
alla socket s. flags può normalmente essere lasciato a zero.
La funzione restituisce il numero di caratteri inviati, oppure -1 in caso di
errore.
int recv(int s, void *buf, int len, unsigned int flags);
buf al massimo len byte provenienti dalla
socket s. flags può normalmente essere lasciato a zero.
La funzione restituisce il numero di caratteri ricevuti, oppure -1 in caso di errore.
Per chiudere una socket si usa la normale funzione close.
Vediamo ora un
 che mostra come si può inviare un messaggio via TCP, ed il corrispondente
che mostra come si fa a riceverlo (questa operazione è un po' più complicata,
ma l'allocazione dinamica della memoria permette di affrontarla senza
problemi!).
che mostra come si può inviare un messaggio via TCP, ed il corrispondente
che mostra come si fa a riceverlo (questa operazione è un po' più complicata,
ma l'allocazione dinamica della memoria permette di affrontarla senza
problemi!).
Per finire, una piccola nota di terminologia:
Spesso si sente parlare di programmazione di rete secondo il
modello client/server. Di che si tratta?
In generale, come abbiamo appena visto, affinché la comunicazione
fra due entità distanti possa avvenire, deve essere in qualche
modo "sincronizzata". A tale scopo il sistema più semplice
(utilizzato nell'esempio) è quello di lasciare perennemente
in attesa di connessione
una delle due estremità.
Aggiungendo a questo fattore "tecnico" il fattore "socioeconomico"
secondo il quale sono molti (possibilmente uno per persona o
scrivania) i punti che richiedono l'accesso a dati o informazioni di
una certa organizzazione, mentre sono decisamente meno i punti
dove le informazioni sono disponibili
(ad esempio poche macchine con un grande serbatoio di disco,
in grado di fare ricerche rapide sui dati disponibili), vediamo come
la funzione di "rendere disponibile un servizio" si specializzi
dal punto di vista dell'hardware (che deve
essere presumibilmente di qualità migliore). Questa specializzazione
hardware porta ad una specializzazione software: è meglio identificare
in modo preciso le due parti
del software che assicura il collegamento fra fruitore e fornitore di
informazioni. Il "client" dovrà adattarsi a funzionare su tutte le "stazioni
da scrivania" (e dunque essere più portabile, e potenzialmente più snello
e semplice), mentre per il "server" dovrà essere approfondita la capacità
di funzionare efficientemente in modo centralizzato.
Se dunque in generale possiamo chiamare
"server" il processo che attende
(magari indefinitamente) che venga stabilito un collegamento di rete,
e "client" il processo che stabilisce tale collegamento, i due programmi
corrispondenti non sono esattamente simmetrici,
ma devono essere progettati tenendo
presente queste esigenze piuttosto sbilanciate. Vedremo fra breve un esempio
più realistico di questa situazione.
Esercizio: Inventare una "transazione" client/server (ad esempio una richiesta di qualche tipo di informazione) e provare a implementarla utilizzando le funzioni di aiuto sopra descritte.