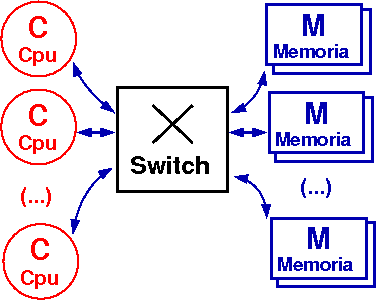
| Memoria condivisa | Memoria distribuita |
 |
 |
| Tipicamente: Bus di memoria locale. | Tipicamente: Connessione di rete. |
| Tipicamente: thread. | Tipicamente: processi distinti. |
| Uso di semafori, lock, condition variables. | Passaggio di messaggi. |
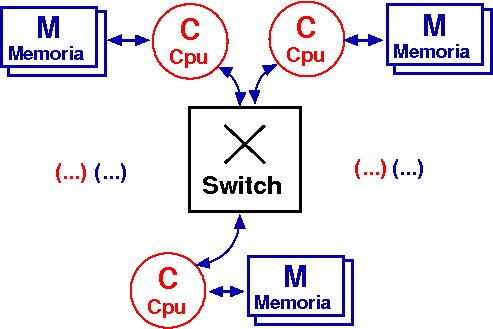
| Memoria condivisa | Memoria distribuita |
|
|
| Tipicamente: Bus di memoria locale. | Tipicamente: Connessione di rete. |
| Tipicamente: thread. | Tipicamente: processi distinti. |
| Uso di semafori, lock, condition variables. | Passaggio di messaggi. |



 vediamo come il problema viene affrontato con le
vediamo come il problema viene affrontato con le TThread
di ROOT. lo stesso problema è invece affrontato con std::thread.
const).